As I promised, here’s the second part of the list, that corresponds to the papers commented in volume II. It was particularly difficult to find PDFs for all of them , and some links go to the publisher which sells the paper for a (in my opinion) substantial amount of money. I encourage you to go to the library, find alternative resources (JSTOR, archive.org…), or ask a colleague. I have most of them if anyone is interested.

The Hill-Robertson’66 paper, one of my all-time-favourites, is not in the list. Actually, Hill didn’t include any of his own papers!
The Bill Hill’s List, part II
Nature of Selection Response
- Castle WE (1905) The Mutation Theory of Organic Evolution, from the Standpoint of Animal Breeding. Science 21:521-525. [PDF]
- Jennings HS (1916) Heredity, Variation and the Results of Selection in the Uniparental Reproduction of DIFFLUGIA CORONA. Genetics 1:407-534. [PDF]
- Sturtevant AH (1918) An analysis of the effects of selection [PDF]
- Castle WE (1919) Piebald rats and selection, a correction. Am Nat 53:370-376. [PDF]
Statistical Predictions of Selection Response
- Lush JL (1935) Progeny Test and Individual Performance as Indicators of an Animal’s Breeding Value. J Dairy Science 18:1-19. [PDF]
- Hazel LN (1943) The genetic basis for constructing selection indexes. Genetics 28:476-490. [PDF]
- Falconer DS (1952) The problem of environment and selection. Am Nat 86:293-298. [PDF]
- Dickerson GE and Hazel LN Effectiveness of selection on progeny performance as a supplement to earlier culling in livestock. J Agric Res 69:459-476. [PDF]
- Henderson CR (1974) General Flexibility of Linear Model Techniques for Sire Evaluation. J Dairy Science 57:963-972. [PDF]
Genetical Prediction of Selection Response
- Fisher RA (1930) The fundamental theorem of natural selection. In: The Genetical Theory of Natural Selection. Oxford Claredon Press. [PDF]
- Haldane JBS (1931) Selection intensity as a function of mortality rate. Proceedings of the Cambridge Philosophical Society 27:131-136 [PDF]
- Comstock RE et al (1949) A Breeding Procedure Designed To Make Maximum Use of Both General and Specific Combining Ability. Agronomy J 41:360-367. [PDF]
- Robertson A (1960) A theory of limits in artificial selection. Roc Soc (Lon) Proc B153:234-249. [PDF]
Results from Selection Experiments
- Dudley JW (1977) 76 Generations of selection for oil and protein percentage in maize. Proc Int Conf Quant Genetics Ames IA, ISU Press, 459-473. [PDF]
- Mather, K (1941) Variation and selection of polygenic characters. J Genet 41: 159–193. [PDF]
- Lerner IM and Dempster ER (1951) Attenuation of genetic progress under continued selection in poultry. Heredity 5:75–94. [PDF]
- Robertson FW (1955) Selection response and the properties of genetic variation. Cold Spring Harbor Symp.Quant. Biol. 20:166–177. [PDF]
- Falconer DS (1960) The genetics of litter size in mice. J Cell Comp Physiol 56(Suppl 1):153–167. [PubMed]
- Clayton GA et al (1957) An experimental check on quantitative genetical theory. I. Short-term responses to selection. J Genet 55:131–151. [PDF]
- Bell, AE et al (1955) The evolution of new methods for the improvement of quantitative characters. Cold Spring Harbor Symp Quant Biol 20:197-211. [PDF]
Selection and Maintenance of Genetic Variation
- Wright S (1932) The roles of mutation, inbreeding, crossbreeding and selection in evolution. Proc VI Int Congress Genetics 1:356-366 [PDF]
- Robertson A (1955) Selection in animals: synthesis. Cold Spring Harb Symp Quant Biol 20:225–229. [PDF]
- Bulmer MG (1971) The effect of selection on genetic variability. Am Nat, 105:201–211 [PDF]
- Lande R (1976) The maintenance of genetic variation by mutation in a polygenic character with linked loci. Genet Res (Camb). 26:221-235. [PDF]
Nature of Quantitative Genetic Variation
- Clayton GA and Robertson A (1955) Mutation and quantitative variation. Am Nat 89:151-158 [PDF]
- Linney R et al (1971) Variation for metrical characters in Drosophila populations III. The nature of selection. Heredity 27:163–174 [PubMed]
- “Student” (1934) A calculation of the minimum number of genes in winter’s selection experiment. Ann Eugenics 6:77–82 [PDF]
- Thoday JM (1961) Location of polygenes. Nature 191:368-370 [PDF]


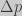 . Let’s assume we have a large population of bacteria, and that for a given locus we have two alternative alleles
. Let’s assume we have a large population of bacteria, and that for a given locus we have two alternative alleles  and
and  with frequencies
with frequencies 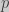 and
and 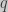 respectively. (Remember that
respectively. (Remember that  .) If
.) If 
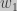 ,
,  and
and  are the fitnesses of allele
are the fitnesses of allele  ;
; 

 the selection coefficient. Substituting, we find and expression for
the selection coefficient. Substituting, we find and expression for 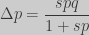
 :
:
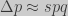
![\Delta \overline{\Phi} = \dfrac{1}{\overline{w}}[cov(w,\Phi) + E(w\overline{\delta})]](https://s0.wp.com/latex.php?latex=%5CDelta+%5Coverline%7B%5CPhi%7D+%3D+%5Cdfrac%7B1%7D%7B%5Coverline%7Bw%7D%7D%5Bcov%28w%2C%5CPhi%29+%2B+E%28w%5Coverline%7B%5Cdelta%7D%29%5D+&bg=cccccc&fg=333333&s=0&c=20201002)
 ) is a function of how traits covariates with fitness (
) is a function of how traits covariates with fitness ( ) and how the parental and offspring traits are related (
) and how the parental and offspring traits are related ( ). By noticing that
). By noticing that  and that
and that 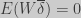 for the haploid case (no inbreeding nor mating):
for the haploid case (no inbreeding nor mating):![\Delta \overline{\Phi} = \dfrac{1}{\overline{w}}[\overline{\Phi}(w-\overline{w})]](https://s0.wp.com/latex.php?latex=%5CDelta+%5Coverline%7B%5CPhi%7D+%3D+%5Cdfrac%7B1%7D%7B%5Coverline%7Bw%7D%7D%5B%5Coverline%7B%5CPhi%7D%28w-%5Coverline%7Bw%7D%29%5D+&bg=cccccc&fg=333333&s=0&c=20201002)
![\Delta p = \dfrac{1}{\overline{w}}[p(w_1-\overline{w})]](https://s0.wp.com/latex.php?latex=%5CDelta+p+%3D+%5Cdfrac%7B1%7D%7B%5Coverline%7Bw%7D%7D%5Bp%28w_1-%5Coverline%7Bw%7D%29%5D+&bg=cccccc&fg=333333&s=0&c=20201002)



 . Hence, the cost matrix has the form:
. Hence, the cost matrix has the form:
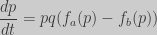
 ;
; 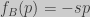

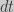 to the right and integrating both sides:
to the right and integrating both sides:
 ) we obtain the classic equation:
) we obtain the classic equation: